A machine-learning photometric classifier for massive stars in nearby galaxies I. The method
Grigoris Maravelias, Alceste Z. Bonanos, Frank Tramper, Stephan de Wit, Ming Yang, Paolo Bonfini
Context. Mass loss is a key parameter in the evolution of massive stars. Despite the recent progress in the theoretical understanding of how stars lose mass, discrepancies between theory and observations still hold. Moreover, episodic mass loss in evolved massive stars is not included in the models while the importance of its role in the evolution of massive stars is currently undetermined.
Aims. A major hindrance to determining the role of episodic mass loss is the lack of large samples of classified stars. Given the recent availability of extensive photometric catalogs from various surveys spanning a range of metallicity environments, we aim to remedy the situation by applying machine learning techniques to these catalogs.
Methods. We compiled a large catalog of known massive stars in M31 and M33 using IR (Spitzer) and optical (Pan-STARRS) photometry, as well as Gaia astrometric information which helps with foreground source detection. We grouped them in 7 classes (Blue, Red, Yellow, B[e] supergiants, Luminous Blue Variables, Wolf-Rayet, and outliers, e.g. QSOs and background galaxies). As this training set is highly imbalanced, we implemented synthetic data generation to populate the underrepresented classes and improve separation by undersampling the majority class. We built an ensemble classifier utilizing color indices as features. The probabilities from three machine-learning algorithms (Support Vector Classification, Random Forests, Multi-layer Perceptron) were combined to obtain the final classification.
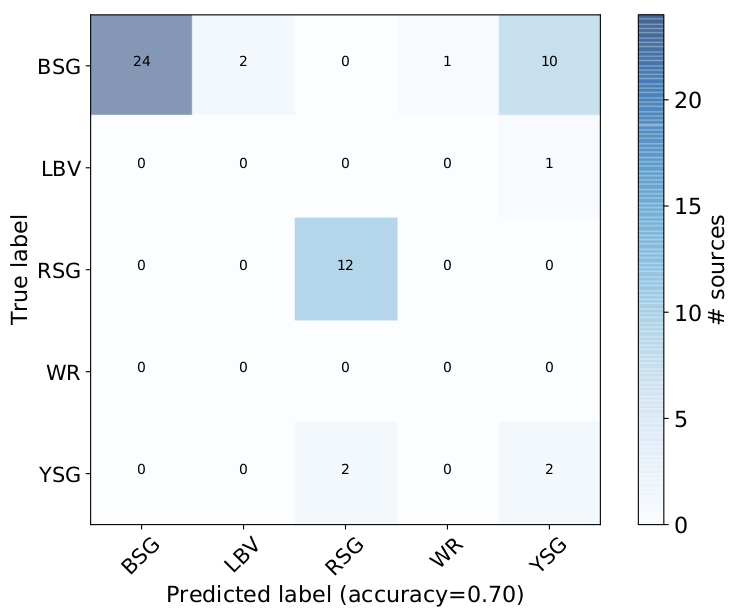
Results. The overall weighted balanced accuracy of the classifier is ∼ 83%. Red supergiants are always recovered at ∼ 94%. Blue and Yellow supergiants, B[e] supergiants, and background galaxies achieve ∼ 50 − 80%. Wolf-Rayet sources are detected at ∼ 45% while Luminous Blue Variables are recovered at ∼ 30% from one method mainly. This is primarily due to the small sample sizes of these classes. In addition, the mixing of spectral types, as there are no strict boundaries in the features space (color indices) between those classes, complicates the classification. In an independent application of the classifier to other galaxies (IC 1613, WLM, Sextans A) we obtained an overall accuracy of ∼ 70%. This discrepancy is attributed to the different metallicity and extinction effects of their host galaxies. Motivated by the presence of missing values we investigated the impact of missing data imputation using simple replacement with mean values and an iterative imputor, which proved to be more capable. We also investigated the feature importance to find that r − i and y − [3.6] were the most important, although different classes are sensitive to different features (with potential improvement with additional features).
Conclusions. The prediction capability of the classifier is limited by the available number of sources per class (which corresponds to the sampling of their feature space), reflecting the rarity of these objects and the possible physical links between these massive star phases. Our methodology is also efficient in correctly classifying sources with missing data, as well as at lower metallicities (with some accuracy loss), making it an excellent tool for accentuating interesting objects and prioritizing targets for observations.
arXiv: 2203.08125